Abstract
Text-to-image diffusion models (T2I) have demonstrated unprecedented capabilities in creating realistic and aesthetic images. On the contrary, text-to-video diffusion models (T2V) still lag far behind in frame quality and text alignment, owing to insufficient quality and quantity of training videos. In this paper, we introduce VideoElevator, a training-free and plug-and-play method, which elevates the performance of T2V using superior capabilities of T2I. Different from conventional T2V sampling (i.e., temporal and spatial modeling), VideoElevator explicitly decomposes each sampling step into temporal motion refining and spatial quality elevating. Specifically, temporal motion refining uses encapsulated T2V to enhance temporal consistency, followed by inverting to the noise distribution required by T2I. Then, spatial quality elevating harnesses inflated T2I to directly predict less noisy latent, adding more photo-realistic details. We have conducted experiments in extensive prompts under the combination of various T2V and T2I. The results show that VideoElevator not only improves the performance of T2V baselines with foundational T2I, but also facilitates stylistic video synthesis with personalized T2I. Our code will be made publicly available.
VideoElevator for improved T2V generation
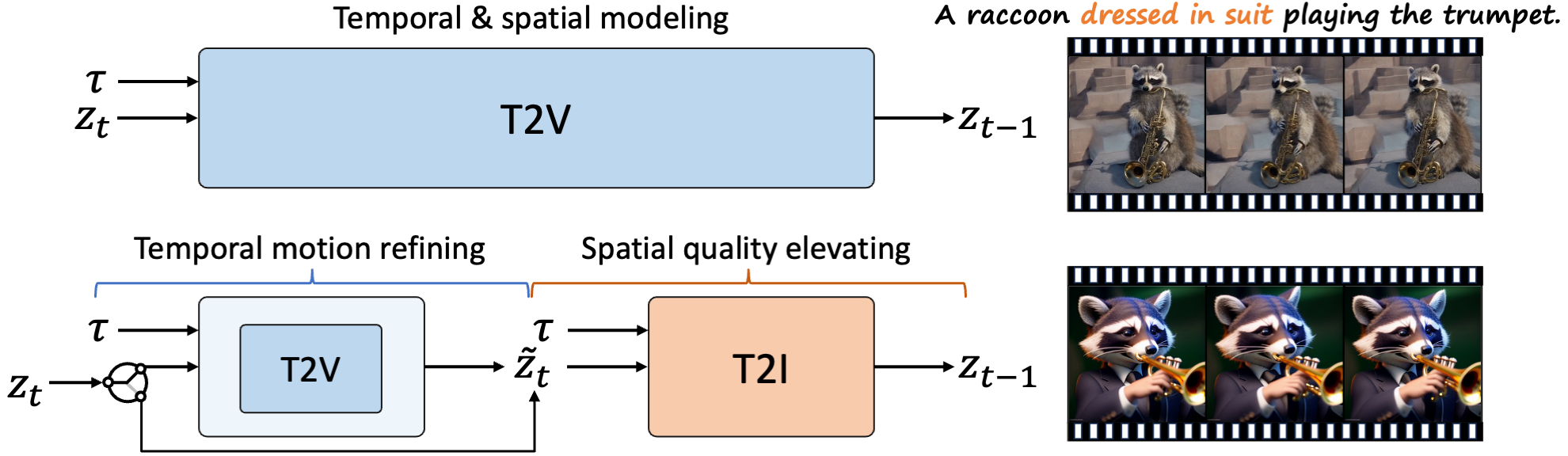
Top: Taking text τ as input, conventional T2V performs both temporal and spatial modeling and accumulates low-quality contents throughout sampling chain.
Bottom: VideoElevator explicitly decompose each step into temporal motion refining and spatial quality elevating, where the former encapsulates T2V to enhance temporal consistency and the latter harnesses T2I to provide more faithful details, e.g., dressed in suit. Empirically, applying T2V in several timesteps is sufficient to ensure temporal consistency.
Results enhanced with foundational T2I
We use Stable Diffusion V1.5 and V2.1-base to enhance T2V baselines.
1. Comparisons with Zeroscope [1]
2. Comparisons with AnimateDiff [2]
3. Comparisons with LaVie [3]
Results enhanced with personalized T2I
We use multiple personalized T2I to enhance T2V baselines, including Lyriel, RCNZCartoon3d, RealisticVision, and ToonYou.
1. Comparisons with Zeroscope [1]
2. Comparisons with AnimateDiff [2]
3. Comparisons with LaVie [3]
Results enhanced with personalized SDXL
We take AnimateDiff XL as baseline and use DynaVision and Diffusion-DPO to enhance it.
Ablation studies
1. Effect of low-pass frequency filter
Prompt: A polar bear is playing bass guitar in snow.
| (a) w/o LPFF | (b) Temporal LPFF (Ours) | (c) Spatial-Temporal LPFF |
|---|---|---|
2. Effect of inversion strategies
Prompt: A raccoon dressed in suit playing the trumpet.
| (a) Add same noise | (b) Add random noise | (c) DDIM inversion |
|---|---|---|
3. Different choice of timestep in temporal motion refining
Prompt: A polar bear is playing bass guitar in snow.
| [] | [45] | [45, 35] | [45, 35, 25] | [45, 35, 25, 15] (Ours) |
|---|---|---|---|---|
4. Different number of timesteps in T2V denoising
Prompt: A polar bear is playing bass guitar in snow.
| N=1 | N=2 | N=4 | N=8 | N=10 |
|---|---|---|---|---|
[1] Zeroscope text-to-video model. https://huggingface.co/cerspense/zeroscope_v2_576w. Accessed: 2023-10-31.
[2] Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023.
[3] Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, et al. Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:2309.15103, 2023.